intro-apache-kafka
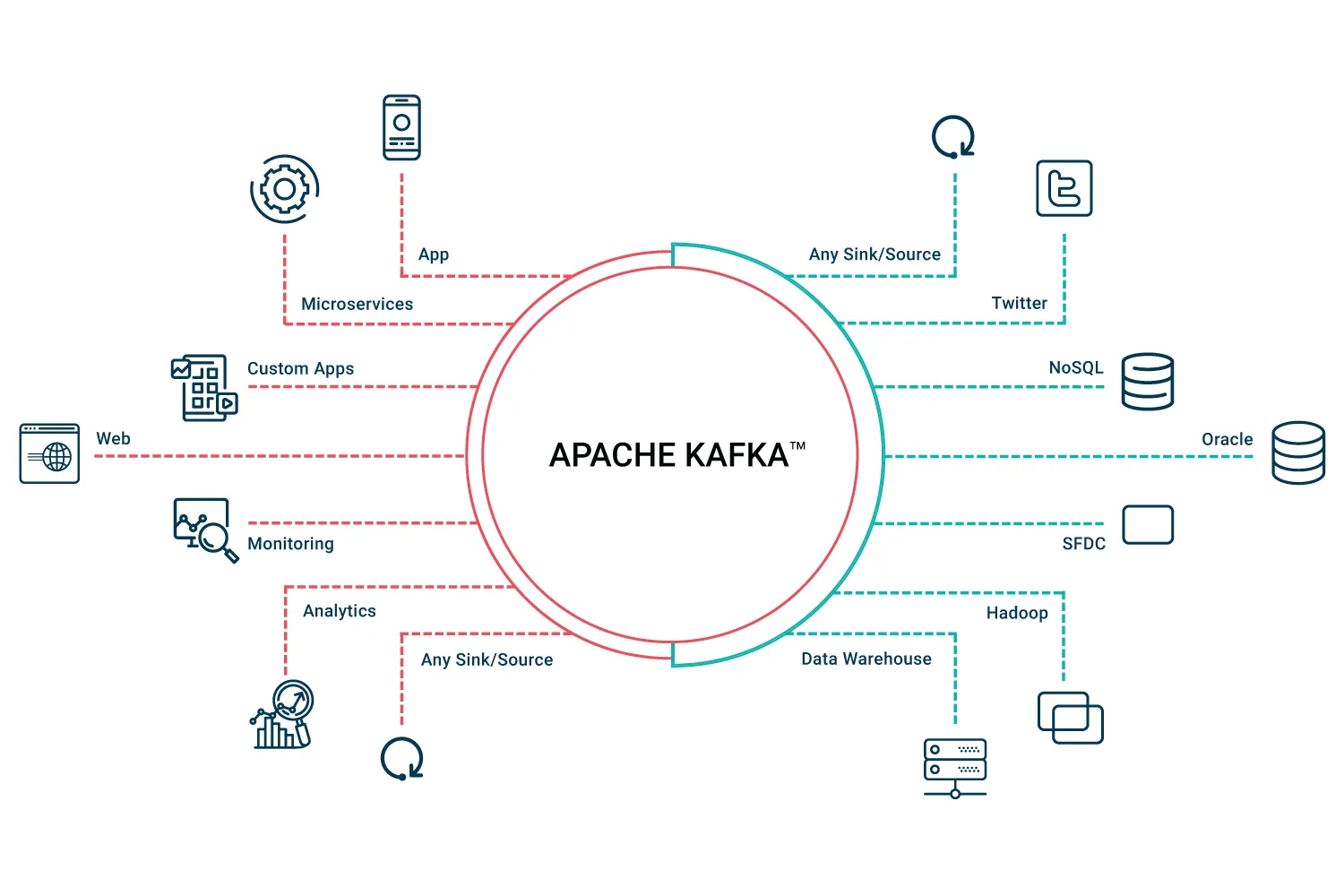
Introduction :
Dans le paysage dynamique de DevOps, où l'échange de données en temps réel, l'évolutivité et la fiabilité sont primordiaux, Apache Kafka apparaît comme un changeur de jeu. Cette plate-forme de traitement de flux open source, née des besoins de LinkedIn et plus tard confiée à Apache Software Foundation, est un acteur clé pour construire des applications robustes, évolutives et réactives. Dans ce guide d'introduction, nous allons plonger dans les principales caractéristiques, les composants de base, et pourquoi les ingénieurs de DevOps devraient se soucier d'intégrer Apache Kafka dans leur ensemble d'outils. Comprendre Apache Kafka Principales caractéristiques:
-
Débit élevé: La capacité d'Apache Kafka à gérer efficacement des volumes de données massifs en fait un choix idéal pour les scénarios impliquant le traitement des mégadonnées.
-
Évolabilité: Kafka s'écaille parfaitement horizontalement et verticalement, en s'assurant qu'à mesure que votre système grandit, Kafka peut s'adapter sans temps d'arrêt.
-
Tolérance des fautes: La plateforme donne la priorité à la sécurité et à la disponibilité des données, même face aux défaillances des nœuds, garantissant des opérations continues.
-
Durabilité: À l'aide d'un journal d'engagement distribué, Kafka assure le stockage persistant des données sur le disque, contribuant ainsi à sa durabilité et à sa fiabilité. Composantes de base:
-
Producteur: L'entité chargée de publier les dossiers sur les thèmes de Kafka.
-
Consommateur: S'abonne à des sujets et traite la forme des enregistrements publiés par les producteurs.
-
Courtier: Serveurs Kafka qui stockent des données et desservent les consommateurs.
-
Gardien du zoo: Gère et coordonne les courtiers Kafka, jouant un rôle crucial dans l'architecture distribuée de la plate-forme.
-
Thème : Représente une catégorie ou un nom d'alimentation auquel les enregistrements sont publiés, en organisant efficacement les flux de données. Pourquoi les ingénieurs de DevOps devraient-ils en prendre en charge?
En tant qu'ingénieur DevOps, l'intégration d'Apache Kafka dans votre arsenal est vitale pour diverses raisons :
-
Pipelines de données en temps réel : Kafka joue un rôle central dans la construction et la maintenance des pipelines de données en temps réel et des applications de streaming, s'alignant sur les exigences agiles de DevOps.
-
Microservices et architecture axée sur les événements: Dans les architectures de microservices, Kafka facilite l'échange de données en temps réel entre différents microservices, favorisant la communication axée sur les événements.
-
Surveillance et abattage : DevOps s'appuie fortement sur la surveillance et l'enregistrement pour l'analyse et l'alerte en temps réel, où Kafka s'avère inestimable dans le traitement efficace des flux de données à grande échelle.
-
Évolitivité et fiabilité : Comprendre l'évolutivité de Kafka est crucial pour construire des applications basées sur le cloud robustes et évolutives, s'alignant sur les principes de base de DevOps. Applications dans DevOps
-
Surveillance continue : Les ingénieurs de DevOps peuvent tirer parti des capacités de Kafka en l'intégrant avec des outils de surveillance, ce qui permet une alerte en temps réel et des contrôles de santé du système pour une résolution proactive des problèmes.
-
Aggrégation des grumes : Kafka sert de solution robuste pour l'agrégation des logarithmes, consolidant les logs de divers services et applications. Cela permet aux équipes de DevOps d'effectuer une analyse en temps réel pour améliorer le dépannage et l'optimisation.
-
Automatisation pilotée par les événements: Kafka peut servir de déclencheur pour des flux de travail et des processus automatisés en réponse à des événements spécifiques au sein du système, contribuant à un environnement DevOps plus réactif et automatisé.
En conclusion, Apache Kafka est un outil polyvalent et puissant pour les praticiens de DevOps, offrant des solutions aux défis liés au traitement des données en temps réel, à l'évolutivité et à la fiabilité du système. L'intégration de Kafka dans votre boîte à outils DevOps ouvre de nouvelles possibilités de création de pipelines résilients, réactifs et efficaces en matière de livraison de logiciels. Restez à l'écoute des prochains articles où nous approfondirons les aspects pratiques de la mise en œuvre de Kafka dans divers scénarios DevOps.